マップとコンテンツが対話的に連動したストーリーマップでも同じ内容を紹介しています。
背景
不動産や土地取引を行う場合、国や行政機関から地価公示データや地価調査データなどの参考値となる価格は公開されていますが、全く同じ条件の不動産は存在しないのが現実的なケースです。ここでは、過去の取引実績データをもとに機械学習を行い、不動産価格(土地取引価格)の予測モデルを構築します。
機械学習による土地利用取引価格の予測
AI や機械学習を用いて予測モデルを構築する際は、大量の学習用データを機械学習ライブラリに投入する必要がありますが、ArcGIS には機械学習の手法を用いたツールが含まれています。
本分析ではそのツールを用いて予測モデルの構築を行います。

学習用データの準備
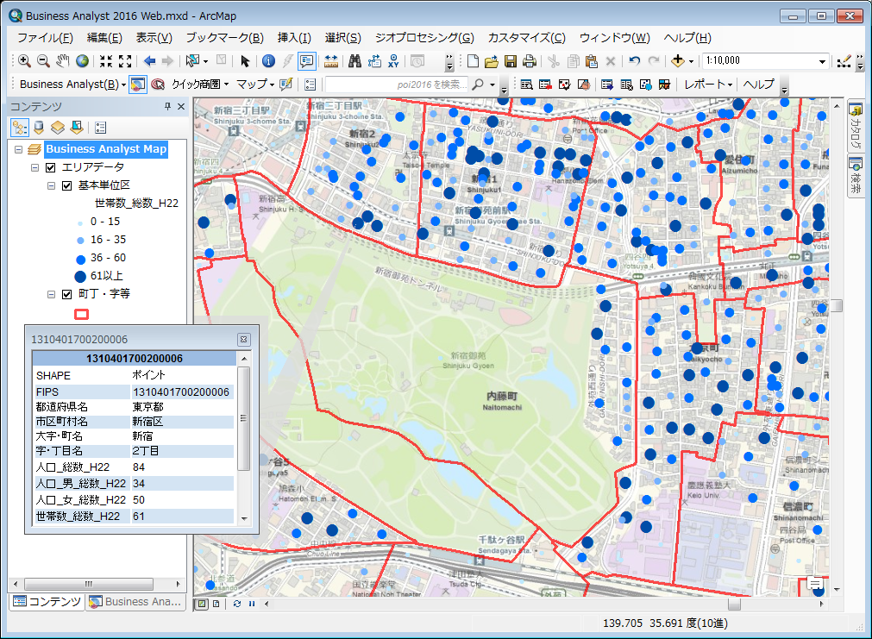
学習用データとして、国土交通省が公開している「土地総合情報システム」で提供されている、不動産取引価格情報のうち、埼玉県内における土地取引、約 45,000 件を学習データとして利用することにしました。
不動産取引価格情報には、取引された不動産に関するさまざまな情報が含まれています。地図上への展開は、住所情報をもとに行うことができます。
・取引価格
・最寄駅名
・最寄駅からの徒歩時間
・土地面積、間口、方位
・土地形状(長方形、etc)
・前面道路 幅員、種別
・住所(町丁・大字レベル)
・etc.
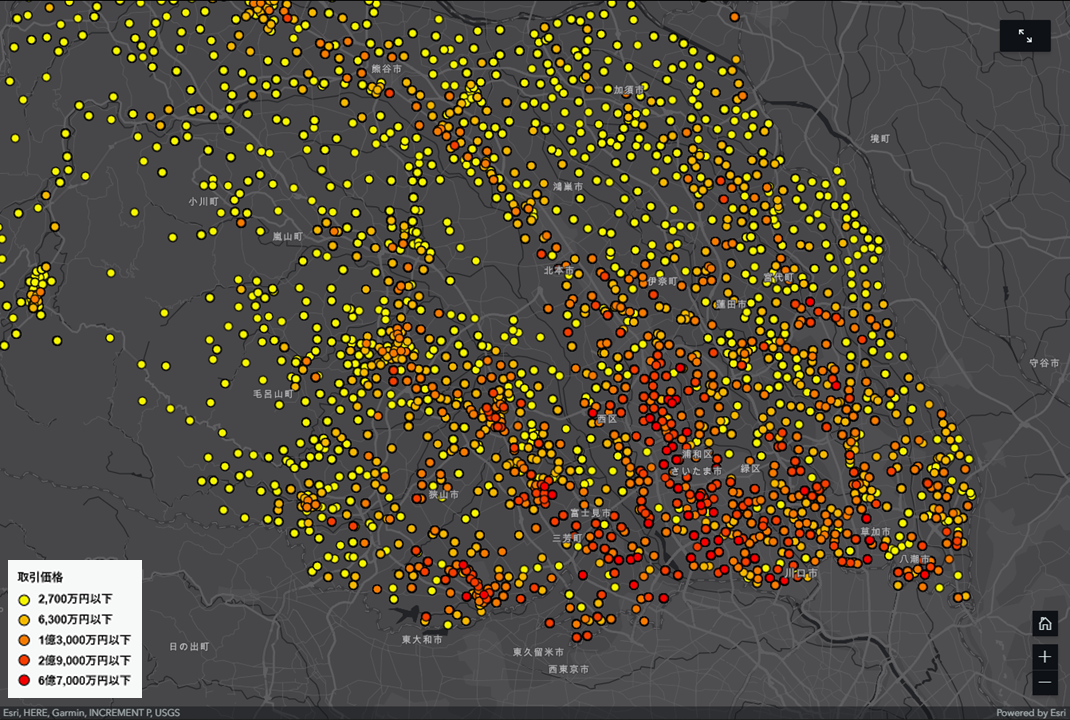
GIS を用いた情報付加
不動産取引価格情報に含まれている属性に加えて、最寄駅の特性を付与して、学習用のパラメーターとして追加します。元々持っている属性情報に GIS を用いて情報を付与することで、予測精度の向上が期待されます。
・人口総数
・人口増減率
・昼間人口
・平均年収
・事業所数、従業者数
・etc.

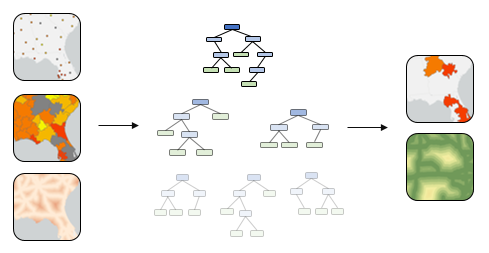
機械学習の手法
機械学習の手法として、ArcGIS に標準搭載されている [フォレストベースの分類と回帰(Forest-Based Classification and Regression)] ツールを用います。このツールは、ランダム フォレストと呼ばれる機械学習手法を用いてモデルを作成し、予測や分類を行うことができます。ここでは、取引価格を予測するように設定して分析を行います。
ランダムフォレストとは?
ランダムフォレストとは、「決定木」と呼ばれる予測モデルを複数組み合わせたアンサンブル モデルであり、機械学習のアルゴリズムの一種です。回帰を行う場合は、各決定木の平均値を予測値として扱い、分類を行う際は、多数決で分類結果を出力します。質的な変数も多く組み込むことができます。
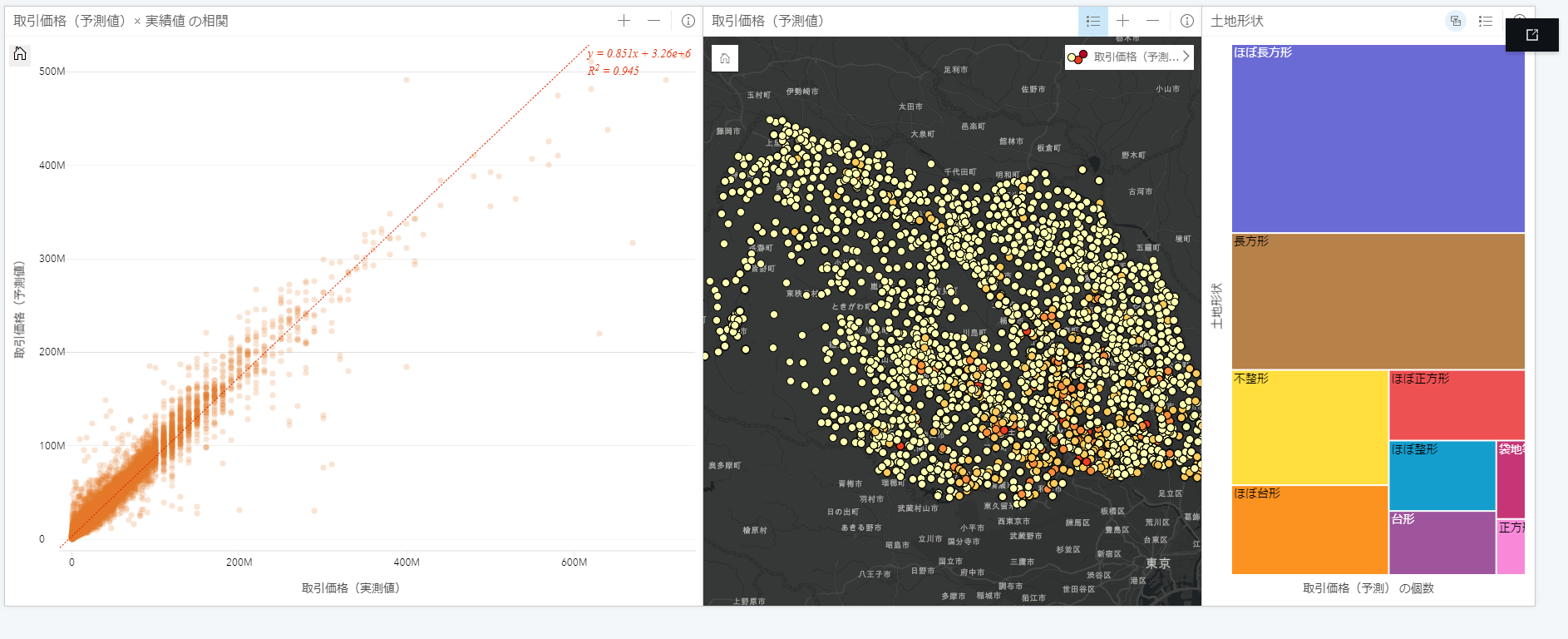
学習結果
[フォレストベースの分類と回帰] ツールを用いて予測モデル構築すると、 実績値と予測値の相関係数が 0.945 と非常に高い正相関を得られるモデルを構築することができました。同じデータを用いて重回帰分析を行った場合は、相関係数が 0.4 程度でしたので、本分析ではランダムフォレストの方が精度よく予測できている結果となりました。
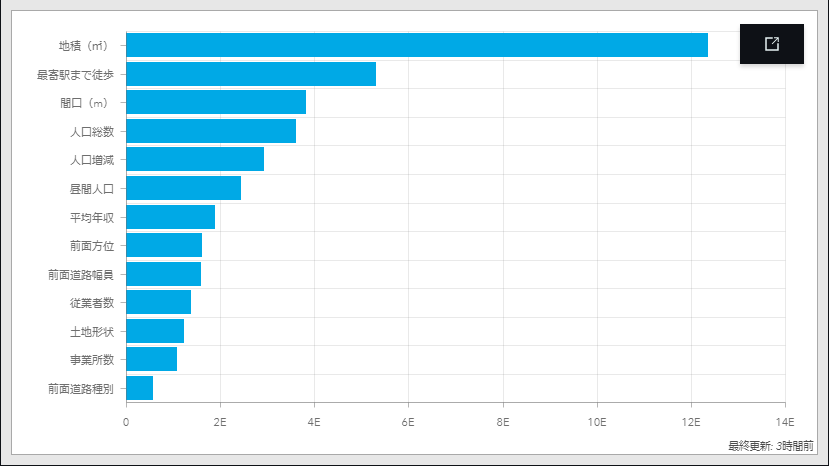
変数の重要度
また、ランダムフォレストで解析した場合、予測モデルに寄与する変数の重要度も同時に出力されます。変数の重要度を確認すると、「地積」(土地面積)や「最寄駅までの徒歩時間」、「間口」などが重要であることが分かります。
それらに加えて、最寄駅の「人口総数」や「人口増減」(平成 22 年 → 平成 27 年の人口増減数)など GIS で追加したパラメーターも重要な変数となっていることが分かります。GIS で情報を付加することで、予測モデルの精度向上に寄与することができました。
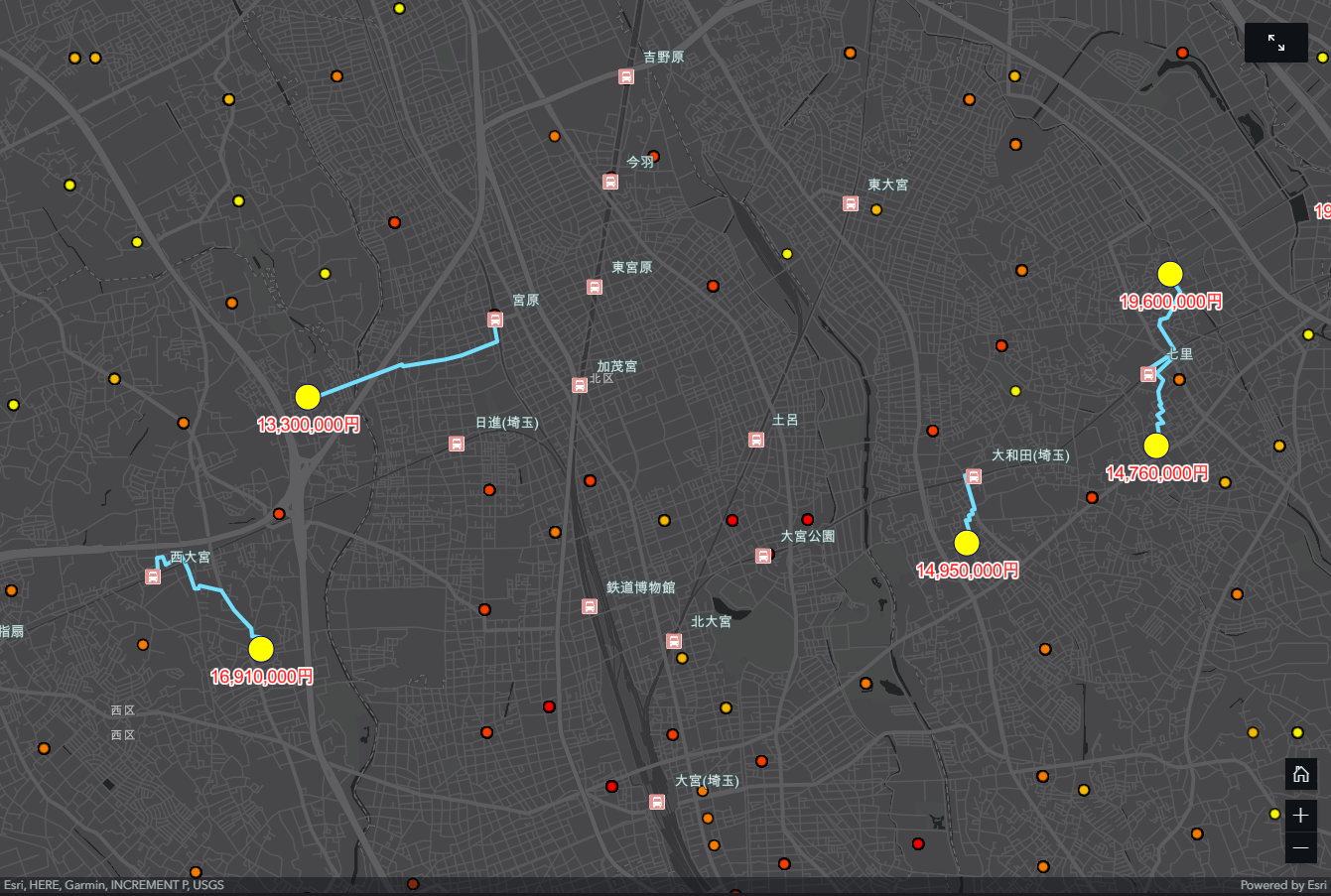
新規物件に対する価格予測
新規物件の情報収集
取引価格の予測を行うためには、予測モデルで使用する変数の収集を行う必要があります。今回のケースでは、土地面積や最寄駅、最寄駅までの徒歩時間、間口、などを収集する必要があります。
GIS で情報付与
GIS 上に情報を展開することで、最寄駅の名称や徒歩距離など、不足している情報を収集することも可能です。
予測モデルの適用
新規物件に対する情報が整備し、構築済みの予測モデルを適用することで、予測値を得ることができます。
このような予測分析を通じて、対象とする物件のポテンシャルを正しく理解し、効率の良い不動産投資を行うことができます。
ランダムフォレスト標準搭載 商圏分析 GIS
ArcGISBusiness Analyst Pro
大規模データの処理やハフモデル等の高度な商圏分析を実現する、デスクトップ型 商圏分析 GIS